No Free Labels: Limitations of LLM-as-a-Judge Without Human Grounding
Michael Krumdick, Charles Lovering, Varshini Reddy, Seth Ebner, Chris Tanner (Kensho Technologies, MIT)
link:https://arxiv.org/abs/2503.05061
(1) A: Good morning, everyone! Today we have Michael Krumdick presenting his recent paper, "No Free Labels: Limitations of LLM-as-a-Judge Without Human Grounding." Michael, the floor is yours for a seven-minute overview.
Part 1: Author Summary
(2) Michael: Thanks for having me. Our work examines limitations of the LLM-as-a-Judge framework, particularly for evaluating response correctness.
The LLM-as-a-Judge framework uses one LLM to evaluate outputs of another LLM. It's popular because it's cheaper than human evaluation and correlates well with human preferences. However, we found a critical limitation: an LLM's ability to correctly answer a question significantly impacts its ability to judge other responses to that same question.
Our main finding is that if an LLM judge can't answer a question correctly itself, it struggles to evaluate whether another model's answer is correct - unless it's provided with a human-written reference answer.
To investigate this, we built a dataset with 1,200 responses across two types of questions:
- Math and reasoning questions from MT-Bench (with corrections to erroneous references)
- A new benchmark we created called BFF-Bench with 160 challenging questions in business and finance
We had human experts annotate all responses for correctness and evaluated how different LLM judges performed under three conditions:
- No reference: Judge evaluates without any reference
- Self-generated reference: Judge uses its own answers as references
- Human-written reference: Judge uses human-verified correct answers
The results were clear: when a judge couldn't answer a question correctly itself, its agreement with human annotators dropped dramatically - unless it was provided with a human reference.
Interestingly, providing a smaller model like Qwen 2.5 7B with high-quality human references led to better judgments than using a larger model like GPT-4o with self-generated references.
Our practical recommendation is straightforward: always provide LLM judges with human-verified reference answers when evaluating correctness. The title "No Free Labels" reflects our conclusion that some level of human verification remains necessary for robust evaluation. [Section 1 and 7]
(3) A: Thank you, Michael. Now we'll explore different aspects of the paper in more detail.
Part 2: First Round of Discussion
(4) Junior: Could you explain what "agreement with human annotators" means in your context and how you measured it?
(5) Michael: We're measuring how often the LLM judge's verdict (correct/incorrect) matches the consensus judgment of our human experts.
We used Cohen's Kappa, which is a statistical measure of inter-rater agreement that accounts for chance agreement. It ranges from -1 to 1, where 1 indicates perfect agreement, 0 indicates random agreement, and -1 indicates perfect disagreement.
In our field, Cohen's Kappa values above 0.6 are considered "substantial agreement," and values above 0.8 are considered "almost perfect agreement."
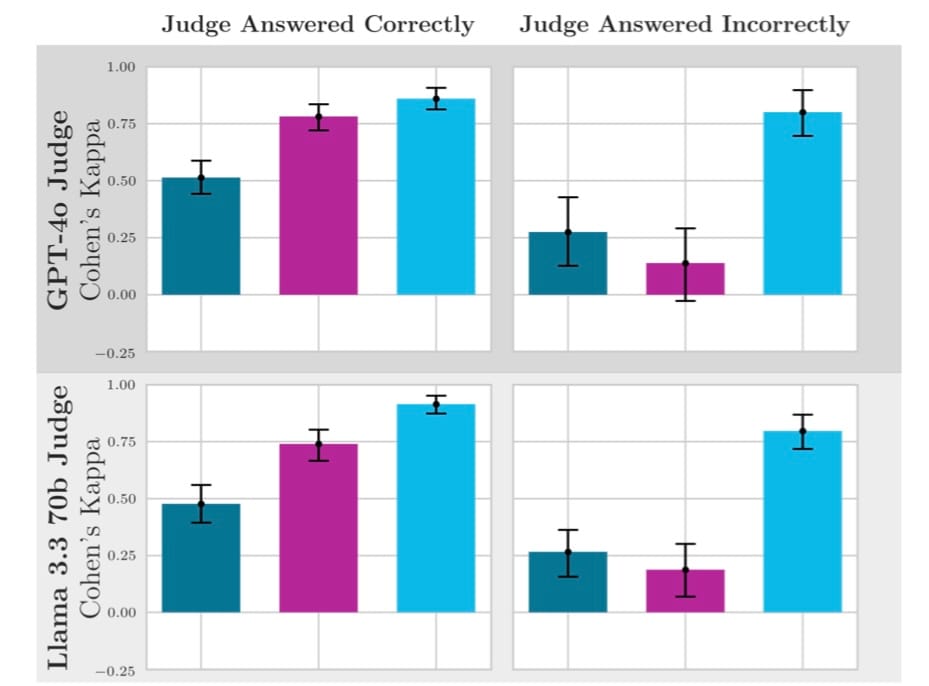
For context, in our pairwise evaluation with human references, our best model (Llama 3.3 70B) achieved a Cohen's Kappa of 0.87, which is excellent. Without references, the same model scored only 0.39, which is considered "fair" agreement at best. [Section 4.4 and 5]
(6) Junior: Did you ever have cases where the human annotators disagreed with each other? How did you handle those?
(7) Michael: Yes, we did have disagreements. For each question-response pair, we collected judgments from three independent annotators who could mark a response as "Correct," "Incorrect," or "Not Sure."
About 54% of questions received unanimous annotations. Another 33% had at most one dissenting annotation. For the remaining 13% of questions that had either no consensus or a consensus of "Not Sure," we deemed these ambiguous and removed them from our analysis.
All annotators had degrees in financial disciplines, making them well-qualified to evaluate responses in our domain. We instructed them to judge responses holistically - if any part was wrong, the entire response should be marked incorrect. [Section 3.3]
(8) HoL: Why did you focus on business and finance for your new benchmark? And why did you choose those specific six models for evaluation?
(9) Michael: We focused on business and finance because correctness is particularly critical in these domains, they combine domain knowledge with quantitative reasoning, and our team has expertise in financial domains.
For models, we deliberately chose a diverse set spanning different families, sizes, and capabilities:
- GPT-4o: A frontier closed-source model
- Llama 3.3 70B: A large open-source model
- Yi 1.5 34B: A medium-sized model from a different family
- Phi-4: A smaller but highly optimized model
- Qwen 2.5 7B: Another medium-sized model
- Gemma 2 2B: A small model to represent the lower end of capabilities
This diversity allowed us to observe patterns across the capability spectrum and different model families. [Section 3.2 and 3.3]
(10) Dr. P: Could you explain how you determined whether a judge answered a question correctly and why you analyzed results through this lens?
(11) Michael: We first collected responses from each model as a candidate answering the benchmark questions. Human annotators determined if these responses were correct or incorrect.
This meant that for each question, we knew whether each model (when acting as a candidate) answered it correctly. Then, when we evaluated that same model as a judge, we could condition our analysis on whether it could answer that specific question correctly.
We analyzed results through this lens based on our hypothesis that a model's ability to correctly answer a question would correlate with its ability to judge responses to that same question.
This revealed a stark difference in judge performance between questions it could and couldn't answer correctly itself. For instance, in the pairwise evaluation, GPT-4o with self-generated references achieved a Cohen's Kappa of 0.78 on questions it answered correctly, but only 0.14 on questions it answered incorrectly.
Providing human references largely eliminated this gap, showing that human grounding can compensate for a judge's knowledge limitations. [Section 5]
(12) LaD: How did you construct BFF-Bench? What criteria did you use for question selection?
(13) Michael: We designed BFF-Bench to be a challenging but unambiguous benchmark with 80 two-turn conversations (160 total questions), all written entirely by hand.
We worked with domain experts in business and finance who crafted questions combining domain knowledge and quantitative reasoning. Each question went through quality control with multiple reviewers verifying its clarity and correctness.
Criteria included:
- Questions needed objectively verifiable answers based on established principles or calculations
- The correct approach and answer should be unambiguous
- Questions should require both domain knowledge and reasoning/calculation
For example, one question asks about IFRS 16 treatment of leased assets, followed by a specific scenario requiring financial statement impact calculation.
Each question took approximately an hour to create, reflecting the care put into crafting well-formed questions with unambiguous correct answers. [Section 3.2]
(14) Senior: What makes your contribution unique compared to other papers on LLM-as-a-Judge?
(15) Michael: While others have noted that LLM judges struggle with difficult questions, our work:
- Systematically investigates the specific mechanism behind why judges struggle - the connection between a judge's ability to answer a question and its ability to evaluate responses
- Quantifies the extent to which human references can mitigate this limitation
- Creates BFF-Bench, a benchmark combining domain expertise with quantitative reasoning
- Analyzes self-preference bias in correctness judgments
- Provides practical recommendations for implementing LLM-as-a-Judge in real-world scenarios
Our work provides deeper mechanistic understanding, quantifies benefits of different reference approaches, introduces a new challenging benchmark, and offers practical guidance. [Section 2 and 7]
(16) Indus: From an industry perspective, doesn't requiring human-verified references defeat the cost benefits of using LLM-as-a-Judge? What's the practical approach here?
(17) Michael: There's an important distinction: verifying references is much less labor-intensive than directly evaluating all model responses. You only need one good reference per unique question, not per response.
Several practical middle-ground approaches:
- Verify a subset of model-generated references: Our results show that verified GPT-4o references performed similarly to human-written references (Cohen's Kappa of 0.61 vs 0.69).
- Target verification efforts: Identify which types of questions your judge struggles with and prioritize creating human references only for those.
- Progressive refinement: Start with model-generated references, have humans verify a subset, and use those to improve your evaluation process.
For high-stakes domains (finance, healthcare, legal), the cost of incorrect information far outweighs verification costs. [Section 7]
(18) MML: Can you formalize the relationship between answering and judging abilities? What does this tell us about fundamental model limitations?
(19) Michael: We can think about this as a relationship between probabilities. If $P_a(q)$ is the probability that a model can correctly answer question $q$, and $P_j(q)$ is the probability it can correctly judge responses to $q$ without a reference, our findings suggest:
$P_j(q) \approx f(P_a(q))$
Where $f$ is some increasing function. When we provide a human reference $r$, the new probability $P_j(q|r)$ becomes much less dependent on $P_a(q)$.
This suggests an inherent bound on reference-free evaluation: if a model lacks knowledge to answer a question correctly, it likely also lacks knowledge to judge other answers to that question.
Models don't have separate "knowledge" and "verification" mechanisms - they're drawing on the same underlying representations for both tasks.
This creates what we might call the "frontier evaluation problem": as we approach the limits of model capabilities, our ability to automatically evaluate those capabilities diminishes precisely when we need evaluation most. [Section 5 and 7]
(20) A: Let's now move into deeper dives on specific aspects of the paper.
Part 3: Deep Dive Discussion
(21) Dr. P: Could you elaborate on what exactly you mean by "references" and how they're used in practice with an example?
(22) Michael: Let me clarify what we mean by "references" and how they're used in the LLM-as-a-Judge framework.
A reference is a sample answer to the benchmark question that's included in the judge model's prompt. It serves as a kind of "answer key" to help the judge evaluate other responses.
Here's a concrete example from our paper. For the question:
"What is the area of a triangle with vertices at (0, 0), (-1, 1), and (3, 3)?"
A human-written reference might look like:
To find the area of the triangle, we can use the formula for the area of a triangle with coordinates A(x1, y1), B(x2, y2), and C(x3, y3):
Area = (1/2) * |(x1(y2 - y3) + x2(y3 - y1) + x3(y1 - y2))|
In this case, the coordinates are A(0, 0), B(-1, 1), and C(3, 3). Plugging these values into the formula, we get:
Area = (1/2) * |(0(1 - 3) + (-1)(3 - 0) + 3(0 - 1))|
Area = (1/2) * |(-0 + -3 - 3)|
Area = (1/2) * |-6|
Area = 3
The area of the triangle is 3.
Then, the judge's prompt would include something like:
[Question]
What is the area of a triangle with vertices at (0, 0), (-1, 1), and (3, 3)?
[The Start of Reference Answer]
To find the area of the triangle...
[The End of Reference Answer]
[The Start of Assistant's Answer]
The area of the triangle with vertices at (0, 0), (-1, 1), and (3, 3) is 3 square units.
[The End of Assistant's Answer]
The judge is instructed to compare the assistant's answer to the reference, identify any mistakes, and determine if the answer is correct or incorrect.
Our study compared three reference conditions:
- "None": No reference was provided
- "Self": The judge used its own answer as the reference
- "Human": A human-written, verified correct answer was provided
We found that when the judge couldn't answer correctly itself, providing a human reference dramatically improved its judging ability. [Section 4.2 and 4.3]
(23) LaD: What types of errors did you find in the original MT-Bench references, and what patterns did you observe?
(24) Michael: In the original MT-Bench, 15 out of 40 math/reasoning questions (35%) had incorrect references. Error types included:
- Calculation errors: Most common were simple calculation mistakes. In Figure 2, the triangle area was calculated incorrectly (0 instead of 3) due to a sign error.
- Logical errors: Flawed reasoning chains with plausible steps but incorrect conclusions.
- Misinterpreted questions: References that solved slightly different problems than asked.
- Inconsistencies: Stating one answer in reasoning but a different one in conclusion.
The errors concentrated in multi-step calculations or complex formulas. Many were subtle - reasoning looked plausible but contained small mistakes that led to wrong final answers.
This pattern reinforces our paper's core message: even references generated by frontier models require verification for reliable evaluation. [Section 3.1]
(25) HoL: How do your findings relate to alignment techniques like RLHF or constitutional AI that also rely on model judgments?
(26) Michael: There's a direct relationship to alignment techniques. RLHF uses reward models to train generators, while constitutional AI uses models to critique their own outputs.
Our work suggests some concerning limitations:
- If reward/critic models can't correctly evaluate difficult questions, they may reinforce incorrect behavior
- This could create a capability ceiling where models can't be optimized beyond the evaluation capabilities of reward/critic models
- Self-preference bias could potentially be amplified through these training processes
Potential improvements:
- Incorporate human-verified references in reward model training for difficult domains
- Target human verification efforts on frontier capabilities
- Be cautious of alignment on domains requiring specialized knowledge
These connections suggest that our findings apply not just to benchmarking but to the entire pipeline of model development, evaluation, and alignment. [Section 7]
(27) Indus: Could BFF-Bench be used for fine-tuning models for business and finance domains? Have you considered extending this to other specialized domains?
(28) Michael: BFF-Bench absolutely has potential for fine-tuning models in business and finance. Its high-quality, human-written questions and answers that demonstrate proper reasoning would be valuable for training.
For extension to other domains like medicine or law, our approach would work well where:
- Correctness is critical
- There are clear right/wrong answers
- Domain expertise is required for evaluation
For medicine, this could include diagnostic reasoning, treatment protocols, or drug interactions. For law, statutory interpretation, case law application, or procedural requirements.
The key principles would remain the same: domain expert-created questions with unambiguous correct answers, gold-standard references, and thorough validation. [Section 3.2 and 7]
(29) Junior: What happens in real-world scenarios where you don't know ahead of time which questions the judge can answer correctly?
(30) Michael: In real-world applications, you could:
- Conservative approach: Always provide human-verified references for all questions.
- Qualification testing: Have your judge model try to answer a small subset of questions first. Use this to identify which question types need human references.
- Difficulty estimation: Create human references for questions above a certain difficulty threshold.
- Domain-specific approach: Always use human references for specialized domains regardless of perceived difficulty.
Our findings show that human references dramatically improve agreement for questions the judge answered incorrectly, while providing modest improvements for questions it answered correctly. This means providing human references is a robust approach across the board.
The good news is that you don't need to create references from scratch - verifying and correcting model-generated references can be almost as effective. [Section 5 and 7]
(31) Junior: I still don't understand why we need references at all. Why can't judges just evaluate answers directly?
(32) Michael: The fundamental issue is that judging correctness requires knowledge of what the correct answer is. If a judge model doesn't know the correct answer itself, it lacks the necessary knowledge to reliably evaluate other responses.
Think of it like grading an exam. If you don't know the correct answer to a question, you can't reliably determine if a student's answer is correct. You need an answer key.
In our experiments, when GPT-4o tried to judge answers to questions it couldn't solve correctly itself, its agreement with human annotators was only 0.28 (Cohen's Kappa) without references. With human references, this jumped to 0.80.
This gap is especially pronounced for difficult questions, which are often the most important to evaluate correctly. References effectively provide the "answer key" that enables reliable evaluation even when the judge lacks the knowledge to solve the problem independently.
Our experiments with "wrong" references further demonstrate this point. When provided with deliberately incorrect references, judge performance dramatically decreased, showing that judges are directly influenced by the reference content. [Section 5 and 6]
(33) Dr. P: Did you analyze patterns in the error rates? Were there specific types of questions where judges performed particularly poorly?
(34) Michael: Yes, we analyzed error patterns through false positive rates (FPR) and false negative rates (FNR) across different reference types.
Judges performed particularly poorly on:
- Complex quantitative reasoning: Questions requiring multi-step calculations showed larger gaps between reference-free performance and with-reference performance.
- Domain-specific knowledge: Questions that required specialized financial knowledge that the models might not have been extensively trained on.
- Self-judgment: Judges showed a strong self-preference bias, with significantly higher false positive rates when judging their own responses versus others' responses.
With self-generated references or no references, models like GPT-4o had nearly 3x higher false positive rates when judging their own incorrect responses compared to others' (around 0.75 vs. 0.25).
Human references reduced this self-preference bias substantially though not entirely.
One interesting finding was an "overruling" behavior where sophisticated judges occasionally identified errors in provided references and made correct judgments despite incorrect references. This was most common with GPT-4o, suggesting more capable models can sometimes detect and override incorrect information. [Section 6]
(35) A: Thank you all for this thorough discussion. Let me summarize the key insights:
- A strong connection exists between an LLM's ability to answer questions correctly and its ability to judge other responses to those questions.
- Providing human-written reference answers dramatically improves judge performance, especially for questions the judge couldn't answer correctly itself.
- The correctness of references matters more than their source—verified LLM-generated references can perform almost as well as human-written ones.
- Self-preference bias is significant, with models rating their own incorrect responses more favorably than others'.
- The "No Free Labels" principle suggests some level of human verification remains necessary for reliable correctness evaluation.
Michael, is there anything else you'd like to highlight?
(36) Michael: Our work suggests that while full automation of evaluation remains challenging, strategic human-AI collaboration can provide a practical middle ground that preserves efficiency while addressing key limitations.
These findings apply not just to benchmark evaluation but to the entire pipeline of model development, deployment, and monitoring. The principles of human grounding through references could be applied to many scenarios where models need to evaluate information quality or correctness.
(37) A: Finally, could you share the five most important citations for understanding the foundational work your paper builds upon?
(38) Michael: Here are the five most important citations:
- Zheng et al. (2023). "Judging LLM-as-a-Judge with MT-bench and Chatbot Arena." Introduced the MT-Bench framework.
- Koo et al. (2023). "Benchmarking cognitive biases in large language models as evaluators." Systematically identified biases in LLM judges.
- Deutsch et al. (2022). "On the limitations of reference-free evaluations of generated text." Provides theoretical foundations for understanding limitations of reference-free evaluations.
- Feuer et al. (2024). "Style outweighs substance: Failure modes of LLM judges in alignment benchmarking." Shows how LLM judges are overly influenced by writing style.
- Krumdick et al. (2024). "BizBench: A quantitative reasoning benchmark for business and finance." Introduced our previous work on challenging benchmarks.
(39) A: Thank you, Michael, and thank you to everyone for participating in today's discussion.