Impact of Pretraining Term Frequencies on Few-Shot Reasoning
Last updated: 2/29/2025
Yasaman Razeghi¹, Robert L. Logan IV¹, Matt Gardner², Sameer Singh¹³ | ¹Department of Computer Science, University of California, Irvine, USA; ²Microsoft Semantic Machines, USA; ³Allen Institute for Artificial Intelligence, USA
link : https://arxiv.org/abs/2202.07206
Discussion:
Attending:
- Author (Yasaman Razeghi)
- HoL (Head of Lab)
- Junior (Junior Student)
- Dr. P (Senior Postdoc)
- Senior (Senior PhD Student)
- MML (Mathematician and Senior ML Researcher)
- A (Assistant)
Part 1: Author's Summary
(1) A: Good morning everyone. Today we have a presentation from Yasaman, who will be sharing her recent work on "Impact of Pretraining Term Frequencies on Few-Shot Reasoning." Yasaman, you have about 7 minutes for your summary, and then we'll open the floor for questions.
(2) Author: Thank you. I'm excited to share our findings on how pretraining data influences few-shot reasoning capabilities in large language models. Our work investigates a fundamental question: when language models perform well on numerical reasoning tasks in few-shot settings, to what extent is this due to their ability to reason versus their ability to exploit statistical patterns from pretraining?
(3) Author: The core hypothesis we explored is that if models truly learn to reason, their performance should be relatively consistent regardless of how frequently the terms in a reasoning task appear in the pretraining data. For example, if a model has learned addition as a generalizable skill, it should perform similarly well on "What is 24 plus 18?" and "What is 23 plus 18?" even if the number 24 appeared much more frequently than 23 in its training data.
(4) Author: Our key finding is quite revealing: across multiple numerical reasoning tasks, we observe significantly better performance on problems containing terms that appear more frequently in the pretraining corpus. In some cases, we see an absolute performance gap of over 70% between instances with the most frequent versus least frequent terms. This suggests that much of what appears to be reasoning may actually be statistical pattern matching. [Section 1]
(5) Author: For our methodology, we focused on three types of numerical reasoning tasks: basic arithmetic operations like addition and multiplication, operation inference where the model needs to determine which operation to perform, and time unit conversions. For each task, we measured how frequently relevant terms appear in the pretraining data of the models we tested.
(6) Author: We defined a metric called "performance gap" that measures the difference in model accuracy between test instances containing the most frequent terms versus those with the least frequent terms in the pretraining data. A model truly capable of reasoning should show a small performance gap. [Section 2]
(7) Author: We ran experiments using several GPT-based models from EleutherAI that were pretrained on the Pile dataset, which is publicly available and allows for this kind of analysis. We used GPT-J-6B as our primary model, along with GPT-Neo-1.3B and GPT-Neo-2.7B for additional comparisons. The consistent pattern across all models was that performance correlates strongly with term frequency. [Section 3]
(8) Author: Our results challenge how we evaluate reasoning capabilities in language models. For instance, in multiplication tasks with GPT-J-6B, we saw a performance gap of around 77% between the most and least frequent terms. Even in simpler tasks like converting decades to years, where the model reached nearly perfect accuracy, we still observed frequency effects during learning. [Section 4]
(9) Author: The implications of our work are significant. First, it suggests that evaluations of reasoning that don't account for pretraining data frequencies may be misleading. Second, it raises questions about what constitutes true reasoning in language models. And finally, it highlights the need for more robust evaluation methodologies that can distinguish between statistical pattern matching and genuine reasoning capabilities. [Section 6]
(10) Author: In conclusion, while large language models have shown impressive few-shot learning capabilities, our work suggests we should be cautious about attributing this to reasoning. The strong correlation between performance and term frequency in pretraining data indicates that these models may be relying more on statistical patterns than on generalizable reasoning skills. [Section 7]
(11) A: Thank you, Yasaman, for that clear summary. I'd now like to open the floor for the first round of questions where we'll go through the different parts of the paper.
Part 2: First Round of Discussion
(12) Junior: I'm a bit confused about the term "few-shot reasoning." Could you explain what this means and how it differs from other types of reasoning in language models?
(13) Author: Great question. Few-shot reasoning refers to a language model's ability to perform a task after seeing only a small number of examples (usually 2-16) in its prompt, without any parameter updates. For instance, we might give the model a couple of examples of multiplication problems with their answers, and then ask it to solve a new multiplication problem.
(14) Author: This differs from zero-shot learning (where no examples are provided) and fine-tuning (where the model's parameters are updated on many examples). The impressive thing about few-shot learning is that it happens "in-context" – the model seems to pick up the pattern from just a few examples in its prompt. What our research questions is whether this capability is truly generalizable reasoning or if it's heavily influenced by statistical patterns the model has seen during pretraining. [Section 2.1]
(15) HoL: Your methodology hinges on measuring term frequencies in the pretraining data. Could you elaborate on how you extracted and calculated these frequencies from the Pile dataset?
(16) Author: We used Amazon Elastic MapReduce to count occurrences of all integers with fewer than seven digits in the Pile dataset, which is about 800GB of text. For single terms like the number "24," we simply counted its occurrences. For co-occurrences like "24" and "hours," we counted instances where both terms appeared within a five-word window of each other.
(17) Author: These counts give us ω{x₁} for single-term frequency, ω{x₁,x₂} for term-pair co-occurrence, and so on. We then ranked all instances by these frequencies and calculated our performance gap metric (Δ) as the difference in average accuracy between instances in the top 10% frequency percentile versus those in the bottom 10%. This approach allows us to quantify how much more accurate the model is on high-frequency versus low-frequency instances. [Section 2.2-2.3]
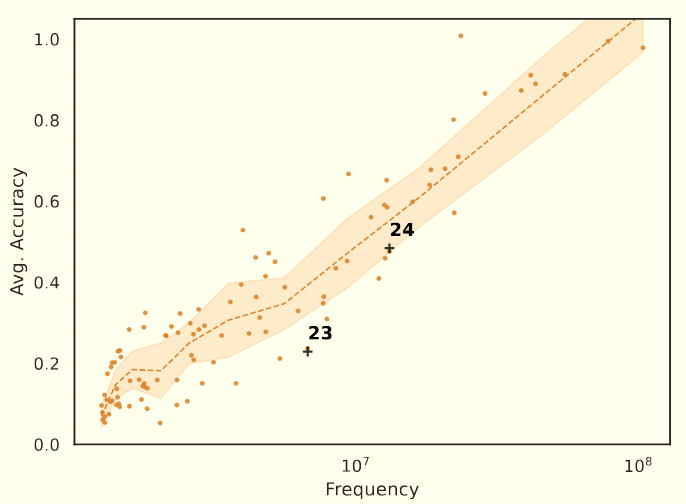
(18) Dr. P: Looking at Figure 1, I notice that even for the "rare" numbers, the frequency is still in the millions. Shouldn't these numbers still be well-represented in the model's training? What's your threshold for considering a term "frequent" versus "rare"?
(19) Author: That's an excellent observation. You're right that even our "rare" terms appear millions of times in the pretraining corpus. We don't use an absolute threshold to define "frequent" versus "rare" – instead, we work with relative frequencies.
(20) Author: What's striking is that despite all these terms being objectively common in the pretraining data, we still see such dramatic performance differences based on their relative frequencies. This suggests the effect might be even stronger than what we're measuring, as truly rare terms might show even larger performance drops. It also highlights how sensitive these models are to the distributional statistics of their training data, even among terms that appear millions of times. [Section 2.2]
(21) Senior: I'm curious about your choice of tasks. Why focus specifically on numerical reasoning tasks rather than other forms of reasoning, and how did you select the specific tasks you included?
(22) Author: We chose numerical reasoning tasks for several reasons. First, they offer clear, objective evaluation criteria – an answer is either correct or incorrect. Second, numerical reasoning has been highlighted in previous work as evidence of language models' reasoning capabilities, particularly in GPT-3 papers.
(23) Author: As for the specific tasks, we selected a spectrum of numerical reasoning challenges with varying complexity. Basic arithmetic tests direct computation skills. Operation inference requires understanding which operation to apply based on examples. Time unit conversions test the model's ability to reason about relations between different units.
(24) Author: These tasks also let us isolate specific terms (numbers and units) whose frequencies we could measure in the pretraining data, making a clean experimental setup. If we can show frequency effects in these relatively straightforward tasks, it raises serious questions about more complex reasoning tasks as well. [Section 3]
(25) MML: The mathematical formulation of your performance gap metric is interesting. Did you consider any alternative metrics or statistical analyses to quantify the relationship between term frequency and model performance?
(26) Author: We did consider alternatives. Our performance gap metric (Δ) compares the extremes (top 10% vs. bottom 10% by frequency), which clearly highlights the effect. We could have used correlation coefficients or regression analysis to quantify the relationship across the full distribution, but the performance gap was more interpretable and directly answered our research question.
(27) Author: In our visualizations (Figures 3-6), we do show the full relationship between frequency and performance, not just the extremes. These scatter plots with fitted curves demonstrate that the relationship is roughly monotonic – higher frequency generally correlates with higher accuracy – though not perfectly linear.
(28) Author: We also considered more complex analyses incorporating higher-order co-occurrence statistics but found that even simple unigram frequencies showed strong correlations with performance, which made our point effectively. More complex metrics would likely show even stronger effects. [Section 2.3]
(29) A: I believe we've covered the main sections of the paper. Let's move to more specific deep-dive questions about particular aspects of the work.
Part 3: Deep Dive Discussion
(30) HoL: Your work raises fundamental questions about how we evaluate reasoning in language models. What do you think would be a more robust evaluation framework that could distinguish between genuine reasoning and statistical pattern matching?
(31) Author: That's an important question. I believe a more robust evaluation framework should include several key components:
(32) Author: First, evaluations should actively control for frequency effects from pretraining. This could involve selecting test instances that deliberately balance high and low-frequency terms, or creating synthetic terms that couldn't have appeared in the training data.
(33) Author: Second, we should develop more sophisticated metrics beyond simple accuracy. Our performance gap (Δ) is one such metric that helps reveal underlying patterns, but we could go further with measures that quantify a model's consistency across semantically equivalent but lexically different prompts.
(34) Author: Third, reasoning evaluations should include systematic interventions – for example, testing whether a model can apply a skill learned with common terms to rare terms, or testing performance on problems that require combining multiple reasoning steps where memorization is unlikely to help.
(35) Author: Finally, I think we need to be more precise about what we mean by "reasoning." In our discussions, we should distinguish between pattern matching, retrieval, and genuine generalization-based reasoning. A truly reasoning-capable system should demonstrate invariance to surface patterns while preserving semantic relationships. [Section 6]
(36) Dr. P: In Table 2, I see that for the multiplication task with k=2 shots, there's a huge performance gap (Δ₁) of 77.6%. But for addition with the same number of shots, the gap is only 16.8%. Why do you think there's such a dramatic difference between these two tasks?
(37) Author: That's a fascinating observation. We believe the difference stems from the inherent complexity of the tasks and how they're represented in the pretraining data.
(38) Author: Addition is a simpler operation than multiplication, and its outcomes follow more regular patterns. For example, adding 1 to any number follows a very predictable pattern. This makes it easier for the model to generalize the operation even to less frequent terms.
(39) Author: Multiplication, by contrast, requires more memorization of specific number pairs and their products. The model seems to have memorized products involving common numbers (like 10, 2, 5, etc.) much better than those involving less common numbers.
(40) Author: Another factor could be the presentation of these operations in the pretraining data. Addition problems and their solutions might appear more consistently across various contexts, while multiplication might be more domain-specific. This hypothesis is supported by our operation inference experiments, where we see the model struggling more to identify multiplication operations compared to addition operations. [Section 4]
(41) Junior: I'm still trying to understand the implications. Does this mean language models can't reason at all, or just that they're not reasoning in these specific numerical tasks?
(42) Author: It's a nuanced point. Our results don't prove that language models can't reason at all, but they do suggest that what looks like reasoning might often be something else – specifically, pattern matching based on statistical regularities in the training data.
(43) Author: For the numerical tasks we studied, the strong correlation between performance and pretraining frequency raises serious doubts about whether the models are truly performing abstract reasoning as opposed to leveraging memorized patterns.
(44) Author: This doesn't rule out the possibility that language models can reason in other contexts or with different architectures or training methods. It does, however, suggest we should be more cautious about claims of reasoning capabilities without controlling for these frequency effects.
(45) Author: I'd say our work shifts the burden of proof: if someone wants to claim a language model is reasoning, they should demonstrate that its performance is invariant to term frequencies or other superficial features of the problem. [Section 7]
(46) Senior: Your study focuses on numerical reasoning, but do you think similar frequency effects would appear in other types of reasoning tasks, like logical reasoning or commonsense reasoning?
(47) Author: While we haven't directly studied those domains, I strongly suspect similar frequency effects would appear in other reasoning tasks. The basic mechanism – models leveraging statistical patterns from pretraining rather than abstract reasoning principles – likely generalizes.
(48) Author: For logical reasoning, frequency effects might manifest in how common certain logical structures or key terms are. For example, performance might be better on inferences using common logical connectives ("if-then," "and," "or") versus less common ones.
(49) Author: For commonsense reasoning, we might see better performance on scenarios involving common objects, relationships, or situations. The model might reason correctly about coffee cups being hot but struggle with less common scenarios that require the same reasoning principle.
(50) Author: I think developing metrics analogous to our performance gap for these other domains would be valuable future work. The challenge is identifying and quantifying the relevant frequency statistics in the pretraining data, which is more straightforward for numbers than for logical structures or commonsense concepts. [Section 7]
(51) MML: The decade-to-year conversion task stands out in your results because it's the one task where the model achieved nearly perfect performance with minimal frequency effects. What do you think makes this task different, and does it offer any insights into when models might truly be reasoning?
(52) Author: The decade-to-year conversion task is indeed an interesting outlier. In this task, the model needs to convert a number of decades to years (e.g., "3 decades = 30 years").
(53) Author: What makes this task different is its simplicity and regularity – it's just appending a zero to the input number. This makes it particularly easy to generalize, even from just a few examples. It's a case where the pattern is so simple that memorization of specific instances becomes less important than grasping the general rule.
(54) Author: This might offer insights into when models are more likely to exhibit true reasoning: when the underlying pattern is simple, regular, and can be accurately captured from just a few examples. In such cases, the model can more easily abstract away from specific instances it has seen during pretraining.
(55) Author: However, I'd note that even in this task, we still observed frequency effects during learning (with fewer shots). It's just that with enough examples, the model eventually reached perfect performance regardless of frequency. This suggests that frequency effects might diminish when a task is simple enough and sufficient examples are provided. [Section 4]
(56) HoL: Your paper mentions that language models are "likely performing pattern matching based on the pretraining data." Could you elaborate on what mechanisms you think are at play here? Is it simple memorization, or something more complex?
(57) Author: I think it's a combination of mechanisms, more complex than pure memorization. Language models don't simply memorize and regurgitate exact sequences they've seen before.
(58) Author: What's more likely happening is that the models are learning distributional statistics around certain terms. For numbers that appear frequently in the pretraining data, the model builds more robust representations of the contexts in which they appear – including their relationships with other numbers and operations.
(59) Author: For example, if "24" frequently appears in multiplication contexts with its correct products, the model learns these associations and can reproduce them in few-shot settings. The few examples in the prompt might simply be activating or priming these pre-existing associations rather than teaching the model a new skill.
(60) Author: This is related to what other researchers have termed "implicit memorization" or "parameterized memorization" – the model encodes statistical regularities in its parameters rather than explicitly storing exact examples. Our work suggests this mechanism plays a much larger role in few-shot reasoning performance than previously acknowledged. [Section 5]
(61) Dr. P: I'd like to understand more about the relationship between model size and these frequency effects. In Figure 6, you compare different model sizes on multiplication tasks. The performance gaps seem to exist across all model sizes, but do you see any trends as models get larger?
(62) Author: Yes, we observed some interesting patterns related to model size. First, as expected, larger models generally perform better on these tasks overall – the 6B parameter model outperforms the 1.3B and 2.7B models.
(63) Author: However, what's striking is that the performance gap persists across all model sizes. Larger models don't seem to overcome the frequency bias; they just get better at both high-frequency and low-frequency instances while maintaining the gap.
(64) Author: We also noticed that smaller models are much more dependent on frequency – they only perform well on the most frequent instances, while their performance on rare instances is close to random. As models get larger, they begin to show non-trivial performance on less frequent instances as well, but the gap remains.
(65) Author: This suggests that scaling alone, at least in the range we studied, doesn't solve the fundamental issue of frequency dependence. Larger models might memorize more patterns and have better representations, but they don't automatically develop frequency-invariant reasoning capabilities. [Section 4]
(66) Senior: Have you considered how prompt engineering might affect these frequency dependencies? Could carefully designed prompts potentially mitigate the performance gaps you observed?
(67) Author: That's an excellent question. We didn't explicitly study different prompt designs in this work, but it's a natural direction for future research.
(68) Author: I suspect that careful prompt engineering could potentially reduce frequency effects in some cases. For instance, prompts that explicitly teach the general rule or algorithm, rather than just providing examples, might help models generalize better to low-frequency terms.
(69) Author: However, I'm skeptical that prompt engineering alone would eliminate the frequency gap entirely. If the model's underlying representations and associations are fundamentally shaped by frequency statistics from pretraining, there might be limits to what prompt engineering can accomplish.
(70) Author: One interesting approach would be to explicitly include low-frequency terms in the prompt examples to see if this helps the model generalize better to other low-frequency terms. This could test whether the issue is with the model's inability to apply rules to rare terms or if it's failing to infer the correct rule in the first place. [Section 6]
(71) MML: Your work shows a correlation between frequency and performance, but correlation doesn't imply causation. Have you considered alternative explanations for the performance gaps you observed?
(72) Author: You raise an important point about causality. While our work demonstrates a strong correlation, we haven't definitively proven that frequency directly causes the performance differences.
(73) Author: One alternative explanation could be that certain numbers have inherent properties that make them both more common in text and easier to process. For example, round numbers and powers of 10 might be both more frequent and easier to compute with.
(74) Author: Another possibility is that there could be confounding variables we haven't accounted for, such as how numbers are typically formatted or used in context.
(75) Author: To address these concerns, we tried to control for number magnitude in our experimental design, and we examined multiple types of frequency statistics (unigram, co-occurrence, etc.) to strengthen our evidence.
(76) Author: While we can't claim definitive causation, the consistency of the pattern across different tasks, models, and frequency measures makes a compelling case that pretraining frequency is at least a major factor in model performance. Future work could use more controlled interventions, perhaps with synthetic pretraining data, to establish causality more firmly. [Section 6]
(77) A: We've had a rich discussion about Yasaman's work. Let me summarize the key insights:
- Language models show significantly better performance on numerical reasoning tasks involving terms that appear more frequently in their pretraining data.
- This effect persists across different model sizes and types of numerical reasoning tasks, with performance gaps sometimes exceeding 70%.
- The findings suggest that what appears to be few-shot reasoning may often be statistical pattern matching based on pretraining frequencies.
- Current evaluation methods for reasoning capabilities in language models may be inadequate if they don't account for pretraining data statistics.
- Scaling model size alone doesn't seem to eliminate the frequency dependence, suggesting this is a fundamental challenge for current approaches.
(78) A: Yasaman, is there anything important about your work that we haven't covered that you'd like to highlight?
(79) Author: I think we've covered the main aspects well. One additional point I'd like to emphasize is the importance of transparency in pretraining data. Our analysis was only possible because the Pile dataset is publicly available. For many commercial models, we cannot perform this kind of analysis because their pretraining data is not disclosed. This limits our ability to understand their behavior and potential biases.
(80) Author: Also, while our work identifies a problem, it also points to potential solutions. By quantifying and understanding these frequency effects, we can work toward models that truly reason rather than just leveraging statistical patterns. This might involve developing new training objectives, architectural innovations, or evaluation methodologies that explicitly account for and mitigate frequency dependencies.
(81) A: Thank you. Could you recommend five key citations that form the foundation for your work?
(82) Author: Certainly. These five papers provide the essential background for understanding our work:
- Brown et al. (2020), "Language Models are Few-Shot Learners" - This introduces GPT-3 and the concept of in-context learning that our work analyzes.
- Gao et al. (2020), "The Pile: An 800GB Dataset of Diverse Text for Language Modeling" - Describes the pretraining dataset we analyzed.
- Feldman (2020), "Does Learning Require Memorization? A Short Tale about a Long Tail" - Provides theoretical foundations for understanding memorization in machine learning.
- Wei et al. (2021), "Frequency Effects on Syntactic Rule Learning in Transformers" - Shows similar frequency effects but in syntactic rather than numerical tasks.
- Gardner et al. (2021), "Competency Problems: On Finding and Removing Artifacts in Language Data" - Discusses the broader issue of artifacts in evaluating language models.
(83) A: Thank you, Yasaman, and thank you everyone for your insightful questions and discussion. This gives us a lot to think about regarding how we evaluate reasoning capabilities in language models.