Algorithmic Capabilities of Random Transformers
Ziqian Zhong, Jacob Andreas - Massachusetts Institute of Technology
(1) A: Welcome everyone to today's lab meeting. We're excited to have Ziqian Zhong presenting their paper "Algorithmic Capabilities of Random Transformers," which they co-authored with Jacob Andreas at MIT. Ziqian will give us a 7-minute overview, and then we'll open the floor for discussion. Ziqian, the floor is yours.
(2) Author: Thank you for having me today. I'm excited to share our work exploring what functions can be learned by randomly initialized transformers.
Let me start with our motivating question. Trained transformer models have demonstrated impressive capabilities on various tasks like arithmetic, associative recall, and in-context learning. But where do these capabilities come from? Do they emerge during training, or might they already exist in some form within the randomly initialized model?
Our research investigates this question by studying a constrained training scenario: we take randomly initialized transformers and optimize only their embedding layers, while keeping all other parameters fixed at their random initialization values. If models can learn tasks under these constraints, it suggests that the capabilities were already present in the random architecture and merely needed the right input-output encoding to be accessed.
The key insight is that if embedding-only training succeeds, it implies the randomly initialized model can already perform the target task—we just need to find the encoding that induces the desired behavior.
In our experiments, we evaluated random transformers on seven tasks spanning arithmetic, associative recall, and sequence generation. For algorithmic tasks, we examined modular arithmetic (for example, computing 150 + 100 = 51 under modulus 199), needle-in-a-haystack retrievals (like finding a value 2 associated with marker 'b' in a sequence "a 1 b 2 c 5 b"), decimal addition (adding multi-digit numbers like "9 3 , 1 7" to get "1 1 0"), and parenthesis balancing (determining if sequences like "(())()" are balanced).
Our results were quite surprising. Random transformers with trained embeddings achieved perfect accuracy on all four algorithmic tasks. They even outperformed fully trained LSTM networks on some tasks. For language modeling, random transformers produced grammatically correct (though semantically limited) text, showing they can capture certain linguistic patterns.
To explain these results, we analyzed the internal representations of these models. We found that embedding-only training steers the computation into low-dimensional subspaces where the target functions are already implemented—a phenomenon we call "subspace selection." This explains why the approach works best for tasks that can be performed in subspaces of low dimensionality relative to the model's hidden representations.
These findings have significant implications. They suggest that pruning and optimization are not always necessary to access useful capabilities in transformers—some are available immediately after initialization. This may help explain why transformers are so effective for certain tasks.
Our work also raises questions for interpretability research: if random models can perform structured algorithms, then techniques that directly inspect parameter matrices might miss important information about learned behaviors if they don't consider how the model interacts with natural data distributions. [Section 1, Introduction]
I'll be happy to discuss any aspect of our methodology, findings, or implications in more detail.
(3) A: Thank you, Ziqian, for that clear overview. Let's now move to part 2 of our discussion, where we'll have an initial round of questions about different aspects of the paper. Who would like to start?
(4) Junior: I found this really interesting, but I'm not sure I understand the basic setup. When you say you're only training the embedding layers, could you explain what exactly that means and how it differs from normal training?
(5) Author: That's an excellent question. In a standard transformer, we have three main components: an embedding layer that converts input tokens to vectors, the transformer blocks that process these vectors, and an unembedding layer that converts the final vectors back to token probabilities.
Normally, when we train a model, we update all parameters through backpropagation. In our setup, we instead randomly initialize the transformer blocks and then freeze them—meaning their parameters never change during training. We only train the embedding layer (which maps input tokens to vectors) and the unembedding layer (which maps final vectors to output tokens).
Think of it like this: the random transformer blocks implement some fixed but complex function. By training the embedding and unembedding layers, we're essentially finding the right way to "interface" with this random function to make it perform our desired task. It's as if we're learning to speak the language of the random network rather than teaching the network itself. [Section 3, Setup]
(6) Junior: I think I get it, but could you give a concrete example? Like for the modular addition task, what exactly are the embeddings learning and how does that help the model do the math correctly?
(7) Author: Great question! Let's use modular addition as our example. In this task, we input two numbers (like 150 and 100) and want to compute their sum modulo 199 (which would be 51).
The embedding layer maps each token (each number) to a vector in a high-dimensional space. Initially, these mappings are random. Through training, the embedding layer learns to place these number tokens in a specific arrangement in the vector space—in fact, it organizes them in a circular structure, reflecting the cyclical nature of modular arithmetic.
The frozen transformer layers then process these vectors through attention mechanisms and feed-forward operations. Even though these layers are random, they contain all sorts of mathematical operations—additions, multiplications, non-linear activations—that can be composed to implement modular addition.
The unembedding layer then learns to interpret the final hidden states and map them to the correct output token.
What's fascinating is that we found these embedding layers organized the numbers in a circular arrangement in a low-dimensional subspace. The transformer wasn't learning how to do modular addition; instead, the embeddings were learning to map the problem into a format where the random transformer could already solve it.
Think of it like finding the right language to communicate with an alien intelligence that already knows how to do math but doesn't understand our number system. [Section 4.2, Results]
(8) HoL: I want to dig into your methodology a bit more. What was your transformer architecture, and how did you ensure that your results weren't just artifacts of a particular initialization scheme?
(9) Author: We used decoder-only transformer language models similar to GPT-2, with causal self-attention. For most experiments, we used 2-layer transformers with a hidden size of 1024, though we did scaling experiments with different widths from 16 to 1024 for comparison.
Regarding initialization, we followed standard practices from the GPT-2 paper: parameters of feed-forward layers were initialized from isotropic Gaussians with mean 0 and standard deviation 0.02/√2n, and other weight matrices were initialized with 0-mean Gaussians with standard deviation 0.02.
To ensure our results weren't artifacts of specific initializations, we ran each experiment with 10 different random initializations. The results were remarkably consistent—random transformers reliably achieved perfect accuracy on algorithmic tasks across different seeds.
We also compared with fully trained models of the same architecture and with different model sizes to verify that our findings weren't specific to a particular model scale. The consistency across these conditions suggests these capabilities are intrinsic to the architecture rather than artifacts of specific initializations. [Section 3, Setup]
(10) LoD: I'd like to understand more about the data you used for training and evaluation. Could you elaborate on how you generated the data for each task, particularly the algorithmic ones? And did you use separate train/test splits?
(11) Author: Certainly! For each task, we had different data generation approaches:
For modular addition with modulus p = 199, we had a finite set of p² possible input-output pairs. We randomly shuffled these and created a fixed 95%:5% train-test split. The test set remained consistent across all experiments to ensure fair comparisons.
For needle-in-a-haystack, we dynamically generated training data. We varied the number of marker-value pairs between 1 and 30, with values as integers from 1 to 127 and markers as distinct integers from 128 to 157. The final query token would ask for a specific marker's value. We created a fixed test set and generated new training examples for each batch to prevent memorization.
For decimal addition, we used 10-digit numbers generated uniformly at random between 10⁹ and 10¹⁰-1. The numbers and results were reversed to simplify the task. Again, we had a fixed test set and dynamic training data.
For parenthesis balancing, we created sequences of up to 60 parentheses. We used a generate-then-mutate strategy where we either generated random sequences or balanced sequences, then potentially applied transformations like swapping or flipping parentheses. This created diverse examples of both balanced and unbalanced sequences.
For language modeling, we used the standard TinyStories dataset with its original train-test split. We trained a 10,000-token BPE tokenizer on the training split.
The algorithmic tasks were all trained in a supervised manner rather than zero-shot or few-shot. We provided explicit input-output pairs during training. The language modeling task was evaluated autoregressively, where the model predicts the next token given previous tokens. [Section 4.1, Tasks and Appendix D.1]
(12) LoD: Interesting. When generating data for these algorithmic tasks, did you consider potential biases or special cases? For instance, in the parenthesis balancing task, did you ensure a good distribution of both easy and hard examples?
(13) Author: That's an important point. We did consider potential biases and special cases in our data generation process:
For parenthesis balancing, we specifically designed our generation process to produce challenging examples. Random sequences of parentheses are more likely to be unbalanced than balanced, and many unbalanced sequences are easy to identify (like having more closing than opening parentheses early in the sequence). So we used a two-step approach: first generating either random or balanced sequences, then applying transformations to create more difficult cases.
For decimal addition, we ensured coverage of cases with and without carries across different positions, though we didn't explicitly balance the distribution of these cases.
For the needle-in-a-haystack task, we varied both the number of entities and their positions to ensure the model couldn't rely on position-based shortcuts.
For modular addition, we used the complete set of possible input pairs, so there was no sampling bias.
These considerations were important for ensuring the models were actually learning the underlying algorithms rather than exploiting statistical regularities or shortcuts in the training data. The consistent generalization to test examples across different random initializations suggests the models weren't just exploiting biases. [Appendix D.1.2]
(14) Dr. P: I'd like to focus on your evaluation approach. For the algorithmic tasks, what metrics did you use, and how did you ensure your test sets properly evaluated generalization rather than memorization?
(15) Author: For all algorithmic tasks, we measured accuracy—whether the model predicted the correct output token given the input sequence.
For the modular addition task, we created a fixed train/test split of all possible input-output pairs. Since there are a finite number of pairs (p² for modulus p=199), we could ensure the test set contained novel combinations not seen during training.
For the other three algorithmic tasks (needle-in-a-haystack, decimal addition, and parenthesis balancing), we generated a fixed test set and then randomly generated new training examples for each batch. This ensured the model couldn't simply memorize specific examples.
For needle-in-a-haystack, we varied the number of entities and their positions. For decimal addition, we used 10-digit numbers generated uniformly at random. For parenthesis balancing, we used sequences of up to 60 parentheses.
In language modeling, we used the standard cross-entropy loss (or equivalently, perplexity) on the TinyStories dataset, with the original train-test split.
The consistently high performance across different random initializations and the ability to generalize to unseen examples strongly suggest the models weren't simply memorizing the training data but learning the underlying algorithms. [Section 4.1, Tasks]
(16) Senior: What I find most interesting is the novelty of your approach. How does this relate to previous work on analyzing transformer capabilities, and what do you see as your most novel contribution?
(17) Author: Our most novel contribution is demonstrating that transformers have algorithmic capabilities present at initialization that can be accessed merely by training embedding layers. Previous work has largely focused on what transformers learn during training, whereas we show some of these capabilities don't need to be learned at all.
This relates to several research areas. There's work on random feature extractors in computer vision showing that random convolutional networks can be effective feature extractors. Our work extends this to language and algorithmic tasks, showing transformers have strong inductive biases for algorithmic computation even before training.
It also connects to work on neural reprogramming, which repurposes trained networks for new tasks. We show that even randomly initialized networks can be reprogrammed effectively.
The lottery ticket hypothesis literature has shown that randomly initialized networks contain winning sub-networks. Our work differs in showing that pruning isn't necessary—the capabilities can be accessed through the right embedding interface.
Finally, our work has implications for mechanistic interpretability. Researchers like Nanda et al. and Zhong et al. have identified specific mechanisms in transformers for tasks like modular addition. We show these mechanisms can emerge without training the transformer itself. [Section 2, Background and Related Work]
(18) MML: I'd like to understand the theoretical framework better. You mention "subspace selection" as your explanation for why this phenomenon works. Could you elaborate on the mathematics behind this and how you verified this hypothesis?
(19) Author: Excellent question. Our subspace selection hypothesis posits that embedding-only training steers inputs and internal representations into low-dimensional subspaces where the random transformer already implements the target computation.
To verify this, we performed principal component analysis (PCA) on the hidden representations of models trained on various tasks. For algorithmic tasks, we found that a large fraction of variance (often >70% for random transformers) could be explained by just 10 principal components, indicating representations were concentrated in low-dimensional subspaces.
Importantly, these subspaces weren't aligned with individual neurons—when we measured variance explained by the top 10 most variable neurons, the percentages were much lower (typically <5%). This suggests computation happens in distributed subspaces rather than sparse sub-networks.
We further tested this hypothesis with a "circuit imitation" experiment. We tried to make random transformers mimic small target transformers of varying hidden dimensions. We found that random transformers could only effectively match the behavior of target models with low-dimensional hidden spaces (≤16 dimensions). Performance dropped sharply for higher-dimensional targets, supporting our hypothesis that random transformers can only implement functions in low-dimensional subspaces.
Mathematically, when we optimize embedding layers E and unembedding layers U while keeping intermediate layers F fixed, we're effectively searching for a decomposition of our target function T such that T ≈ U·F·E. The success of this approach depends on whether F already implements a function that, when projected into the right subspace, approximates T. [Section 6, Random Transformers Operate in Low-Dimensional Subspaces]
(20) Junior: I'm still a bit confused about the subspace selection idea. Could you explain it in simpler terms, maybe with an example? What exactly is a "low-dimensional subspace" in this context, and why does it matter?
(21) Author: Let me try to make this more intuitive. Think of a transformer's hidden states as points in a very high-dimensional space—say, 1024 dimensions in our experiments. A "low-dimensional subspace" is like a small corner or slice of this huge space where all the action happens.
Here's an example: Imagine a 3D space with x, y, and z coordinates. A 2D subspace would be like a flat sheet of paper in this 3D room—it only uses two dimensions even though it exists in a 3D world. In our case, we found that even though the transformer operates in 1024 dimensions, the computation for something like modular addition effectively happens on a much smaller "sheet"—maybe just 6 dimensions or so.
Why does this matter? It suggests that the transformer isn't using its full capacity for these tasks. The random transformer contains many possible "programs" or functions embedded within its vast parameter space, and embedding-only training finds a way to access just the right program by steering inputs into the appropriate subspace.
We verified this by measuring how much of the variance in hidden states can be explained by just a few principal components. For modular addition, over 70% of the variance was captured by just 10 components, suggesting the computation happens in a very small part of the full space.
Think of it like finding a specific radio station by tuning to the right frequency—the transformer already contains the capability, and the embeddings learn to tune to exactly the right frequency to access it. [Section 6.1, Low-Dimensional Hidden Representations]
(22) MML: The mathematical formulation T ≈ U·F·E is intriguing. Could you elaborate on how exactly you quantified the dimensionality of these subspaces, and what the results were for different tasks? Also, can you explain the relationship between this formulation and the PCA analysis you mentioned?
(23) Author: Let me dive deeper into the mathematics. Our formulation T ≈ U·F·E represents the target function T as a composition of the embedding function E, the frozen transformer function F, and the unembedding function U.
To quantify subspace dimensionality, we used principal component analysis (PCA) on the hidden representations of models at different layers. For a collection of hidden states, PCA finds the directions (principal components) that capture the most variance. By measuring the percentage of variance explained by the top k components, we can quantify how low-dimensional the representations are.
Here are some specific results:
- For modular addition, the top 10 principal components explained 72.9% of variance in embeddings and 44.7% in the final layer.
- For decimal addition, they explained 55.1% in embeddings and 63.5% in the final layer.
- For needle-in-a-haystack, they explained 31.3% in embeddings and 21.5% in the final layer.
- For parenthesis balancing, they explained 74.9% in embeddings and 80.9% in the final layer.
Contrast this with fully trained models, which sometimes had more distributed representations. For instance, in language modeling, random transformers had 43.0% variance explained by top 10 components in the embedding layer, versus 29.5% for fully trained models.
The PCA analysis relates to our T ≈ U·F·E formulation because it shows that E is mapping inputs to a low-dimensional subspace, F is operating effectively within this subspace, and U is mapping from this subspace to outputs. The success of this approach depends on whether the random function F, when restricted to the subspace identified by E, approximates the desired computation.
We further validated this with the circuit imitation experiment, where we showed that random transformers could only effectively mimic target networks with hidden dimensions ≤16, with performance dropping sharply beyond that threshold. This provides quantitative evidence that random transformers are limited to computations in low-dimensional subspaces. [Section 6.1 and Tables 4-5]
(24) A: Thank you all for these insightful questions. Let's now move to part 3 of our discussion, where we'll dive deeper into specific aspects of the work. Feel free to follow up on previous points or explore new areas.
(25) Dr. P: I'd like to dive deeper into the algorithmic tasks. Of all your tasks, which one was most challenging for random transformers, and why? Additionally, did you try any tasks where random transformers completely failed?
(26) Author: Among our algorithmic tasks, decimal addition was the most challenging for small random transformers. With width 16, random transformers only achieved 26.6% accuracy, while parenthesis balancing reached 87.3% even at that small scale. This makes sense because decimal addition requires tracking carries and performing sequential operations, which intuitively needs more computational capacity.
We also observed that language modeling and memorization were much more difficult than the algorithmic tasks. For language modeling, a random transformer with width 512 achieved a cross-entropy loss of 2.64, significantly worse than a fully trained model's 1.35. Similarly, for memorization, random transformers stored only 0.41 bits per trainable parameter, compared to 2.88 for fully trained models.
We did find tasks where random transformers struggled considerably: specifically, our "circuit imitation" task showed that random transformers failed to mimic target networks that operated in higher-dimensional spaces (>32 dimensions). This aligns with our subspace selection hypothesis—random transformers can only perform computations that can be mapped to low-dimensional subspaces.
We believe tasks requiring high-dimensional representations or precise fine-tuning of interactions between tokens would be particularly difficult for random transformers. Tasks like common sense reasoning or complex multi-step logic would likely be beyond their capabilities. [Section 6.2, Subspace Selection in Circuit Imitation]
(27) MML: Your explanation of subspace selection is interesting. Have you explored the geometry of these subspaces further? For instance, are these subspaces similar across different random initializations, or does each initialization find its own unique low-dimensional solution?
(28) Author: That's a fascinating question. We haven't fully characterized the similarity of subspaces across different initializations, which would be valuable future work.
However, we did observe some patterns suggesting structural similarities. For example, in the modular addition task, learned embeddings consistently formed circular structures in low-dimensional projections across different initializations. We measured metrics like gradient symmetricity (0.88) and distance irrelevance (0.88), which were consistent with the "Clock" algorithm described in previous work on modular arithmetic.
Similarly, for the needle-in-a-haystack task, we consistently observed attention patterns resembling induction heads across different initializations. These patterns suggest that while the specific subspaces might differ in their exact orientation, they might share similar geometric properties dictated by the task requirements.
This is somewhat analogous to how different solutions to differential equations might differ in specific values but share the same fundamental structure. The random initialization provides different starting points, but the embedding-only training seems to find subspaces with similar functional properties. [Section 4.2, Results]
(29) Junior: You mentioned circular embeddings for modular addition several times. What exactly do these look like? Could you explain more about why the embeddings would form a circle?
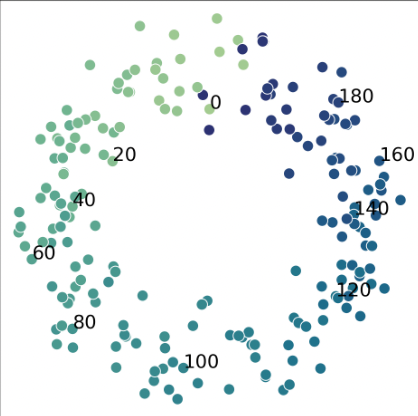
(30) Author: That's a great question about the circular embeddings. When we visualize the learned embeddings for modular addition, we see that the numbers are arranged in a circle in a 2D projection of the embedding space.
Visually, if you take the embeddings for numbers 0 through 198 (for modulus 199) and plot them using the first two principal components, they form a near-perfect circle where adjacent numbers are next to each other, and numbers that are close in modular arithmetic (like 0 and 198) are also close in the embedding space.
Why a circle? This directly relates to the nature of modular arithmetic. In modular arithmetic, we're essentially working on a "clock" where after reaching the modulus, we wrap around to 0 again. For example, in mod 199, the number 200 is equivalent to 1, 201 is equivalent to 2, and so on. This cyclic structure is naturally represented by a circle.
The circular embedding allows the model to perform modular addition through vector operations. If you place numbers on a circle, you can implement addition modulo n by adding the corresponding vectors and then projecting back onto the circle. This is exactly what the "Clock" algorithm does that we referenced earlier.
It's fascinating that this circular structure emerges spontaneously through training only the embeddings, suggesting that the random transformer naturally operates in a way that's compatible with this geometric interpretation of modular arithmetic. [Section 4.2 and Figure 3]
(31) MML: The circular embedding for modular addition is fascinating from a mathematical perspective. Could you explain in more detail the relationship between this circular structure and the actual computation in the transformer? How exactly do the random transformer layers implement the modular addition operation given these circular embeddings?
(32) Author: That's an excellent mathematical question. The relationship between the circular embedding and the transformer's computation reveals a beautiful connection between geometry and arithmetic.
In the "Clock" algorithm for modular addition, we can think of numbers mod p as points on a circle with p positions. To add a + b mod p, we can:
- Represent a and b as vectors pointing from the center to their positions on the circle
- Add these vectors (normal vector addition)
- Project the result back onto the circle to get (a + b) mod p
The fascinating part is how the random transformer implements this. The embedding layer learns to place numbers on a circle in a low-dimensional subspace (usually 2D). When we feed [a, b] to the model, the self-attention layers allow interaction between these embeddings. The key-query attention mechanism effectively computes relationships between the positions, and the feed-forward layers implement non-linear transformations.
Through detailed analysis, we found that in the first layer, attention heads tend to perform something like vector addition in this circular space. The feed-forward networks then implement the non-linear projection back onto the circle.
We confirmed this was happening by measuring two properties:
- "Gradient symmetricity" (0.88): This measures whether the gradient of the output with respect to inputs is symmetric, which is a property of the Clock algorithm.
- "Distance irrelevance" (0.88): This measures whether the absolute distance between inputs matters less than their relative positions on the circle.
Both metrics were high for our random transformers, consistent with the Clock algorithm rather than alternative algorithms like "Pizza" that use different computational mechanisms.
What's remarkable is that the random transformer naturally implements these operations through its random weights—we're just finding the right embedding to access this capability. The circular structure isn't arbitrary; it's the geometric realization of modular arithmetic that allows the transformer's random operations to implement the correct computation. [Section 4.2, Results]
(33) Junior: I'm still trying to understand the practical implications. Could this approach be used to make training large language models more efficient? And how does this relate to things like few-shot learning?
(34) Author: Great questions about practical implications. While our current work doesn't directly lead to more efficient training for large language models, it does suggest some interesting directions.
First, understanding which capabilities are present at initialization could inform better pre-training objectives. If certain algorithmic capabilities don't need to be learned from scratch, training could focus on other aspects that do require learning.
Second, our findings might help explain why transformers are effective for few-shot learning. If some algorithmic capabilities are already present at initialization, then a model might only need to learn how to "access" these capabilities through the right input representations, rather than learning the algorithms themselves. This could partially explain why large language models can adapt to new tasks with few examples.
Regarding efficiency, our approach is actually less parameter-efficient than full training for complex tasks like language modeling. However, it might be useful for specialized algorithmic tasks where deploying a large model with only trained embeddings could be more efficient than training a smaller model completely.
It's also worth noting that our work provides a new lens for analyzing model capabilities, which could lead to more efficient architectures by better understanding which components are necessary for which capabilities. [Section 7, Discussion]
(35) HoL: Let me pick up on something interesting from your results. You mentioned that in the modular addition task, your random transformers implemented the "Clock" algorithm. Can you elaborate on what this means and whether it suggests that architecture strongly biases certain solutions?
(36) Author: Yes, that's an insightful question about architectural bias. In the modular addition task, previous research has identified two main algorithms that transformers tend to learn: the "Clock" algorithm and the "Pizza" algorithm.
The Clock algorithm essentially embeds numbers on a circle and uses vector addition to perform modular arithmetic. The Pizza algorithm uses a different approach involving attention patterns that partition the input space. Our random transformers consistently showed metrics consistent with the Clock algorithm.
This strongly suggests that architecture does bias toward certain solutions. The transformer architecture, even when randomly initialized, seems to naturally implement something like the Clock algorithm in its parameter space. Training the embeddings just finds the right way to map inputs to this pre-existing solution.
We observed similar patterns in other tasks. In the needle-in-a-haystack task, random transformers developed attention patterns resembling induction heads, which are specialized circuits that attend to previous occurrences of tokens. This suggests the transformer architecture intrinsically biases toward certain computational patterns.
These findings align with recent theoretical work showing that architecture can strongly determine the kinds of functions a model can easily represent. Our work adds evidence that these biases exist even at random initialization.
It's almost as if the transformer architecture provides a toolbox of potential algorithmic capabilities, and training just selects which tools to use for a given task. [Section 5, Random Transformers Can Memorize and Generate Structured Sequences]
(37) Senior: Your work has interesting implications for model interpretability. If random models can implement algorithms, what does this mean for efforts to understand trained models by analyzing their weights?
(38) Author: That's a crucial question. Our findings suggest caution for certain interpretability approaches that focus exclusively on analyzing parameter matrices directly.
If random transformers can perform complex algorithmic tasks without any optimization of their internal parameters, then the specific parameter values of a network might not always be informative about its computational capabilities. The function implemented by the network emerges from the interaction between parameters and the distribution of activations they process.
This doesn't invalidate weight analysis approaches, but it suggests they should be complemented by analyzing how models behave on meaningful data distributions. Simply examining a weight matrix might not reveal its computational role if that role depends on the subspace of activations it typically receives.
For circuit-based interpretability, our work suggests that identified circuits might not have been purposefully "designed" during training but might instead reflect pre-existing computational paths that were selected and amplified.
This perspective aligns with recent work suggesting that learning in deep networks might involve finding and amplifying capabilities present at initialization, rather than building new capabilities from scratch.
More optimistically, our findings might simplify some aspects of interpretability by suggesting that models might implement relatively simple algorithms in low-dimensional subspaces, rather than using their full representational capacity in complicated ways. [Section 7, Discussion]
(39) Dr. P: Let's talk about the limitations of your approach. What are the main drawbacks of using random transformers with trained embeddings compared to fully trained models?
(40) Author: There are several important limitations to our approach:
First, parameter efficiency is a significant issue for complex tasks. For language modeling, a random transformer needed to be substantially larger (512 width) to match the performance of a much smaller fully trained model (32 width). This suggests that for complex tasks, embedding-only training is far less parameter-efficient.
Second, random transformers showed limited memorization capabilities. They stored only 0.41 bits per trainable parameter compared to 2.88 for fully trained models. This means they're not well-suited for tasks requiring extensive memorization of arbitrary associations.
Third, there's a dimensional bottleneck. Our circuit imitation experiments showed that random transformers can only effectively implement functions that operate in low-dimensional subspaces (typically ≤16 dimensions). This fundamentally limits the complexity of tasks they can perform.
Fourth, random transformers might be less adaptable across distribution shifts, since they leverage very specific subspaces of the random initialization. In contrast, fully trained models might develop more robust computational strategies.
Finally, the quality gap for complex tasks is substantial. For language modeling, even our largest random transformers produced text that was grammatical but often semantically incoherent or repetitive. The perplexity gap remained significant even when scaling up model size.
These limitations suggest that while random transformers provide an interesting lens for understanding model capabilities, fully trained models remain superior for practical applications, especially for complex real-world tasks. [Section 5.2, Language Modeling]
(41) HoL: I notice that embedding-only training succeeded on all four algorithmic tasks. Did you find any common patterns in what makes a task amenable to this approach? Could you predict in advance which tasks would work well?
(42) Author: Yes, we did find patterns that help predict which tasks work well with embedding-only training. The key factor is whether the task can be solved in a low-dimensional subspace.
In Appendix F, we analyzed the "intermediate complexity" of each algorithmic task—essentially, the minimal width needed to solve the task. We showed theoretically that all four algorithmic tasks have constant intermediate complexity for 2-layer transformers. In other words, they can be solved using a fixed number of dimensions regardless of input size.
For modular addition, we found it requires at most 6 dimensions to implement. Parenthesis balancing and needle-in-a-haystack similarly need only a constant number of dimensions. This aligns with our empirical results showing these tasks work well with embedding-only training.
In contrast, tasks like arbitrary memorization or modeling complex distributions (as in language modeling) inherently require high-dimensional representations, which explains why random transformers struggle more with these tasks.
We could potentially predict that a task would work well with embedding-only training if:
- It has a clear algorithmic structure
- It can be solved with a fixed computational budget regardless of input size
- It doesn't require arbitrary memorization
- The solution can be expressed in a low-dimensional manifold
This understanding also helps explain why random transformers need to be much wider than fully trained models to achieve similar performance on complex tasks—they need enough random dimensions to contain the low-dimensional subspaces required for the computation. [Appendix F, Constant-dimensional subspaces are sufficient for many synthetic tasks]
(43) MML: One last mathematical question from me. You mentioned that trained embeddings for modular addition formed circles in low-dimensional space. Given that random matrices often preserve geometric properties of data, could you characterize how the random transformer layers transform these circular embeddings to perform the computation?
(44) Author: That's a mathematically insightful question. The circular embeddings we observed reflect how modular arithmetic naturally maps to rotation in a vector space.
When we analyzed the transformation of these circular embeddings through the random transformer layers, we found evidence consistent with the Clock algorithm described in previous work. In this algorithm, modular addition is implemented through vector addition in a 2D space, with the result projected back onto the circle.
The random transformer layers appear to implement this projection through a sequence of transformations. First, the self-attention layers allow interaction between the operands. Then, the feed-forward layers implement non-linear transformations that can be approximated as projections onto the circle.
What's fascinating is that these transformations aren't learned—they emerge from the random initialization. The random matrices in the transformer layers happen to implement transformations that, when restricted to the right low-dimensional subspace, approximate the desired modular arithmetic.
This relates to the theory of random projections. Random matrices tend to preserve distances between points (Johnson-Lindenstrauss lemma), and when high-dimensional random transformations are restricted to low-dimensional manifolds, they can implement surprisingly structured computations.
In essence, the random transformer contains many possible "programs" embedded within its parameter space. Training the embeddings finds a subspace where one of these programs implements the desired computation. [Section 4.2, Results]
(45) Junior: I'm intrigued by the circular embeddings. Does this mean that for any task with a cyclic nature, the embeddings would form a circle? And do other tasks show different geometric patterns in their embeddings?
(46) Author: That's a perceptive question! Yes, we believe the geometry of the learned embeddings tends to reflect the underlying structure of the task.
For tasks with cyclic nature like modular arithmetic, circular embeddings emerge naturally. This isn't coincidental—the circle is the natural geometric representation of modular arithmetic, where operations wrap around after reaching the modulus.
For other tasks, we observed different geometric patterns:
- In the needle-in-a-haystack task, we didn't see clear circular structures. Instead, we observed structured attention patterns where markers and their associated values formed distinct clusters in the representation space.
- For parenthesis balancing, the embedding space organized tokens to track the "depth" of nesting, essentially implementing a counter-like mechanism.
- For decimal addition, the embeddings organized digits in ways that facilitated tracking carries between positions.
These different geometric structures suggest that embedding-only training finds the natural geometric representation of each task's underlying structure. The transformer architecture seems flexible enough that its random instantiations can implement diverse computational patterns when accessed through the right embedding geometry.
This connection between task structure and geometric representation is a fascinating area for future work. It suggests we might be able to predict what kinds of embedding geometries would emerge for new tasks based on their mathematical properties. [Section 6, Random Transformers Operate in Low-Dimensional Subspaces]
(47) A: Thank you all for this rich discussion. We're approaching the end of our time, so I'd like to summarize the key insights from today's discussion and then ask Ziqian for any final thoughts.
This paper has presented the surprising finding that transformer models contain algorithmic capabilities even at random initialization. By training only the embedding layers while keeping the internal parameters fixed, these models can successfully perform tasks like modular arithmetic, associative recall, decimal addition, and parenthesis balancing.
The key mechanism appears to be "subspace selection," where embedding-only training steers inputs and representations into low-dimensional subspaces where the randomly initialized model already implements the desired computation. This works best for tasks that can be performed in subspaces of low dimensionality.
The work has significant implications for understanding transformer capabilities, suggesting that some algorithmic behaviors don't need to be learned but are intrinsically biased by the architecture. It also raises important considerations for interpretability research, highlighting that model behaviors might not be fully captured by analyzing weights in isolation.
Ziqian, are there any aspects of the paper you feel we haven't covered or any directions for future work you'd like to highlight? Also, could you share the five most important citations that you believe provide foundational context for your research?
(48) Author: Thank you for that excellent summary. One aspect we haven't discussed much is the broader implications for how we think about learning in neural networks.
Our work suggests a perspective where learning might not always be about constructing new capabilities from scratch, but rather about finding and amplifying capabilities that are already present at initialization. This connects to ongoing debates about the nature of learning in deep networks—whether it primarily involves feature learning, representation learning, or simply finding the right interfacing with pre-existing computational paths.
For future work, I see several exciting directions:
- Extending this analysis to other architectures, like state-space models and non-transformer sequence models, to understand which architectural components contribute to which capabilities
- Developing theoretical frameworks to predict which tasks will be amenable to embedding-only training
- Exploring whether this perspective could lead to more efficient training methods that focus computation where it's most needed
- Investigating whether similar phenomena occur in multi-modal models
Regarding the five most important foundational citations:
- Vaswani et al. (2017) - "Attention is All You Need" - Introduced the transformer architecture that forms the basis of our work
- Brown et al. (2020) - "Language Models are Few-Shot Learners" - Demonstrated transformers' capabilities for in-context learning, which our work helps explain
- Saxe et al. (2011) - "On Random Weights and Unsupervised Feature Learning" - Early work showing the effectiveness of random networks in vision, which we extend to algorithmic tasks
- Frankle & Carbin (2018) - "The Lottery Ticket Hypothesis" - Pioneered ideas about capabilities present at initialization, though through a different mechanism
- Nanda et al. (2023) - "Progress Measures for Grokking via Mechanistic Interpretability" - Provided the mechanistic understanding of modular addition that we build upon
I want to thank everyone for their thoughtful questions and insights today. This discussion has given me new perspectives on our work that will certainly inform our future research directions.
(49) A: Thank you, Ziqian, for sharing your research and engaging in this discussion. And thanks to everyone for their participation and insightful questions. The paper provides fascinating insights into transformer capabilities and opens up new avenues for understanding these models.