A Unified Conversational Agentic Language Model
Authors and Affiliations:
- Emre Can Acikgoz¹, Jeremiah Greer², Akul Datta¹, Ze Yang¹, William Zeng², Oussama Elachqar², Emmanouil Koukoumidis², Dilek Hakkani-Tür¹, Gokhan Tur¹
- ¹University of Illinois Urbana-Champaign
- ²Oumi
link: https://arxiv.org/abs/2502.08820
Dialogue
A: Good morning everyone! Today we have a presentation from Emre, who will be sharing their recent work on developing a unified conversational agentic language model called CoALM. Emre will give us a 7-minute overview, and then we'll open the floor for questions. Emre, whenever you're ready.
Author: Thank you. I'm excited to share our work on CoALM: A Unified Conversational Agentic Language Model. Our paper addresses a fundamental question: Can a single model master both multi-turn conversations and tool use? This question emerged from our observation of two parallel tracks in LLM research that rarely intersect.
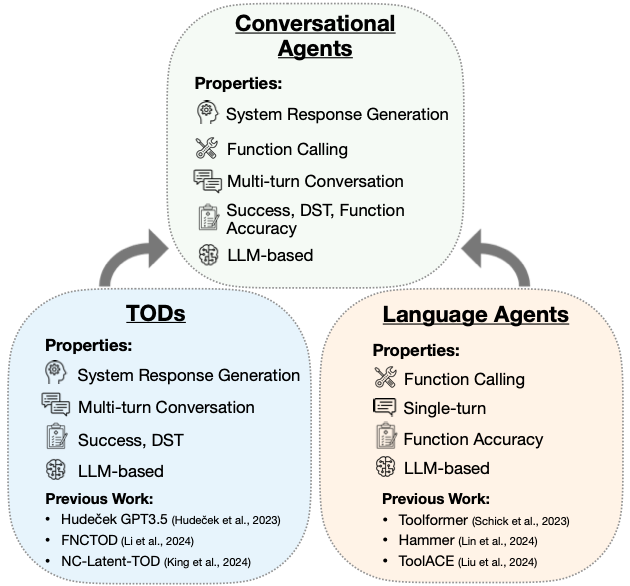
On one side, we have Task-Oriented Dialogue (TOD) systems that excel at multi-turn conversations but are typically limited to predefined APIs. On the other side, we have Language Agents (LAs) that can flexibly use a wide range of tools but often struggle with coherent multi-turn dialogue.
Our research shows that these capabilities are complementary rather than conflicting. We've developed CoALM, a unified approach that integrates the strengths of both TOD systems and LAs.
For our methodology, we created CoALM-IT, a carefully constructed multi-task dataset that interleaves multi-turn ReAct reasoning with complex API usage. This dataset spans three dimensions: dialogue state tracking, complex function calling, and multi-turn conversations in ReAct style. The novelty of CoALM-IT comes from its Conversational ReAct API (CRA) instances, which makes it the first multi-turn TOD dataset explicitly incorporating ReAct-style reasoning with multiple think steps inside [Section 1].
Using this dataset, we fine-tuned three models with different parameter sizes: CoALM 8B, CoALM 70B, and CoALM 405B. For evaluation, we conducted experiments on three complementary benchmarks: MultiWOZ 2.4 for TOD tasks, and API-Bank and BFCL V3 for LA tasks [Section 4].
Our results demonstrate that CoALM models outperform specialized models across both domains. Specifically, our larger-scale variants (CoALM 70B and 405B) outperform GPT-4o and other domain-specific models on both TOD and function calling benchmarks. This shows that unifying conversational and agentic capabilities in a single model is not only feasible but beneficial [Section 5].
The implications are significant: instead of developing separate systems for dialogue and tool use, we can create unified agents capable of maintaining coherent multi-turn conversations while flexibly leveraging diverse tools. This approach eliminates the need for expensive retraining or prompt engineering when introducing new services [Section 6].
A: Thank you, Emre, for that excellent overview. Let's now open the floor for questions. We'll start with a first round to explore different aspects of the paper.
HoL: Thanks for the presentation, Emre. I'm particularly interested in your methodological approach. You mentioned CoALM-IT as a multi-task dataset. Could you elaborate on the rationale behind combining these specific data types, and how this approach differs from previous efforts to integrate dialogue and tool-use capabilities?
Author: Great question. Our methodology stems from identifying the key skills needed for both effective dialogue and tool use. When we analyzed the limitations of existing approaches, we found that TOD systems like FNCTOD are typically trained on a small dataset restricted to domain-specific APIs for state tracking. Meanwhile, language agents like Toolformer or Hammer are optimized for function calling but lack multi-turn dialogue capabilities.
We designed CoALM-IT to address these complementary weaknesses by combining three types of data: SNIPS for dialogue state tracking, Hammer and ToolACE datasets for function calling, and our novel Conversational ReAct API (CRA) dataset for integrating reasoning with API calls in multi-turn settings.
What sets our approach apart is that we're not just concatenating these datasets – we're interleaving them during training, allowing the model to continuously practice different skills without overfitting to any single domain. This contrasts with previous approaches that either focus exclusively on dialogue management or function calling skills in isolation.
The key innovation is our CRA dataset, which extends the traditional ReAct format with two distinct reasoning steps (Thought1 before API call and Thought2 after receiving results) specifically designed for multi-turn dialogue scenarios [Section 4.1].
Junior: I'm still trying to understand the difference between TOD systems and Language Agents. Could you explain these concepts in simpler terms and why it's difficult to combine them?
Author: Absolutely! Let me break this down with an example.
Think of a TOD system as a hotel concierge who's really good at having conversations about a few specific tasks – like booking rooms or arranging airport shuttles. This concierge maintains context across multiple turns of conversation ("How many guests?" followed by "What dates?") and tracks what you want throughout the conversation. However, if you ask about something outside their domain – like stock prices – they'd struggle because they're trained only on hotel-related functions.
In contrast, a Language Agent is like a tech-savvy assistant who can use many different tools (APIs) to help you. They can look up weather, set reminders, or search for information by calling the right tool for the job. However, they tend to treat each request as a standalone task and aren't as good at maintaining context across multiple turns of conversation.
The difficulty in combining them stems from their different training objectives. TOD systems are optimized for dialogue flow and state tracking but with limited APIs, while Language Agents prioritize choosing the right tool from many options but don't maintain dialogue context well.
Our CoALM approach unifies these capabilities by teaching a single model to both maintain dialogue context and flexibly use a wide range of tools [Section 3.1].
Dr. P: I'd like to dig into your evaluation approach. You tested on MultiWOZ 2.4, API-Bank, and BFCL V3. Could you explain the specific metrics you used for each benchmark and why they're relevant? Also, I noticed in Table 2 that CoALM 70B achieved 43.8% JGA on MultiWOZ while CoALM 405B got 38.8%. What explains this discrepancy despite the larger model size?
Author: Excellent questions about the evaluation. For MultiWOZ 2.4, we used two primary metrics: Success Rate, which measures whether all user-requested information is successfully provided, and Joint Goal Accuracy (JGA), which evaluates the model's ability to track dialogue states accurately across turns.
For API-Bank, which focuses on function calling, we used Rouge-L as the primary metric, along with Rouge-1, Rouge-2, and BLEU-4 scores. We evaluated at two levels: L-1 (invoking a known API) and L-2 (retrieving and calling from multiple candidates).
For BFCL V3, we evaluated on several metrics including Overall Accuracy, Abstract Syntax Tree Accuracy, Executable Function Accuracy, Live Accuracy, Multi-Turn Accuracy, and Relevance/Irrelevance Detection. These metrics help us understand different aspects of function calling capabilities [Section 5.1].
Regarding the discrepancy between CoALM 70B and 405B on JGA, the CoALM 405B results represent a checkpoint from just one completed epoch, as the model was still in training when we submitted the paper. We believe with complete training, the 405B model would likely surpass the 70B variant.
Second, this could reflect the inherent challenges in optimizing for multiple skills simultaneously. The 405B model might have developed stronger function calling capabilities (note its 100% accuracy on relevance detection in BFCL V3) while temporarily sacrificing some dialogue state tracking performance [Section 5.2].
Senior: I'm intrigued by your claim that CoALM can "master both multi-turn conversations and tool use." What exactly do you consider the novel contribution here? Many existing models like GPT-4 can handle both conversations and tool use to some degree. How does CoALM fundamentally advance the state of the art?
Author: That's a crucial question about our contribution. While models like GPT-4 can indeed handle both conversations and tool use to some degree, our work advances the state of the art in several key ways:
First, we provide empirical evidence of a critical gap between TOD and LA capabilities. Our systematic evaluation across three benchmarks demonstrates that existing specialized models excel in one domain but significantly underperform in the other. Even powerful models like GPT-4o show this imbalance [Section 5.2-5.3].
Second, we introduce a novel training approach through CoALM-IT, particularly the CRA component. This is the first multi-turn TOD dataset that explicitly incorporates ReAct-style reasoning with multiple thought steps. We systematically transform each dialogue turn to include reasoning before API calls (Thought1) and after receiving results (Thought2), extending the traditional ReAct format specifically for multi-turn dialogue [Section 4.1].
Third, our ablation studies in Table 5 provide insights into the importance of each dataset component. Removing any component significantly affects performance in specific tasks, confirming that each element contributes uniquely to the model's capabilities [Section 5.4].
The key innovation isn't just that CoALM can handle both conversations and tool use – it's that it achieves state-of-the-art performance across both domains simultaneously without sacrificing performance in either. Our larger models outperform even GPT-4o across all three benchmarks [Section 5].
LaD: I'd like to focus on the dataset construction. You mentioned creating CoALM-IT with a hybrid approach. Could you detail how you ensured quality control for the CRA dataset that was generated using GPT-4o? And what criteria guided your processing of existing datasets like SNIPS, Hammer, and ToolACE?
Author: Great question about our dataset quality assurance. For the CRA dataset, which is our most novel component since it was generated using GPT-4o, we implemented a systematic validation process.
We randomly sampled 100 dialogue instances and evaluated them against a predefined set of 51 available functions covering transportation, booking, entertainment, and utility services. We asked a senior Computer Science student to evaluate these samples across four key dimensions: undefined function calls, incorrect argument types, argument hallucination, and low-quality reasoning/planning.
Our evaluation showed a 9% error rate, with most issues occurring in restaurant reservations where key details like restaurant names or dining times were occasionally missing. These errors stemmed primarily from argument hallucination and low-quality reasoning. We systematically collected feedback to identify areas for improvement [Appendix D].
For processing existing datasets, we applied several criteria: For SNIPS (originally designed for language understanding), we transformed it into state tracking instruction tuning format by crafting detailed instruction prompts. This yielded 24,542 samples for dialogue state tracking [Section 4.1].
For Hammer and ToolACE, we preserved their original function calling capabilities but standardized their format for consistency. Hammer's dataset incorporates random noise in function and parameter names to prevent overfitting, forcing the model to reason about API functionality through descriptions rather than memorizing identifiers. We post-processed these datasets by incorporating prompt instructions and adding conversation history where available [Section 4.1].
Junior: I'm trying to understand how the ReAct-style reasoning you mentioned works. Could you explain this with a simple example from your dataset? What are these "thought" steps, and how do they help the model make better decisions?
Author: That's a great question for clarification. ReAct stands for "Reasoning and Acting," and it's an approach where models explicitly break down their thinking process before taking actions.
Let me walk through a simplified example from our CRA dataset to illustrate:
Imagine a user says: "Yes, please tell me how to get tickets for the Jazz Festival."
In a traditional system, the model might directly jump to an API call or response. But with our ReAct-style reasoning, the process includes explicit thought steps:
- Thought1: "The user is interested in purchasing tickets. I need to call the BuyEventTickets API for the Jazz Festival."
- This is the reasoning that happens BEFORE making an API call
- It helps the model explicitly consider what action is appropriate
- Action: BuyEventTickets(event_name='Jazz Festival', number_of_seats=2, date='2023-10-07', city='New York')
- This is the actual API call with parameters
- Observation: {'status': 'success', 'message': 'Successfully purchased 2 tickets'}
- This is the result received from the API
- Thought2: "The tickets were successfully purchased. I need to confirm this with the user."
- This is reasoning AFTER receiving the API result
- It helps the model interpret the result and decide what to tell the user
- System: "You have successfully purchased 2 tickets for the Jazz Festival in Central Park!"
- This is the final response to the user
These explicit thought steps help the model in several ways:
- They break complex reasoning into interpretable steps
- They force consideration of when to call APIs versus responding directly
- They provide reasoning both before and after API calls
- They connect dialogue context with appropriate actions
This approach is especially valuable in multi-turn settings because it helps maintain coherence across the conversation [Section 4.1].
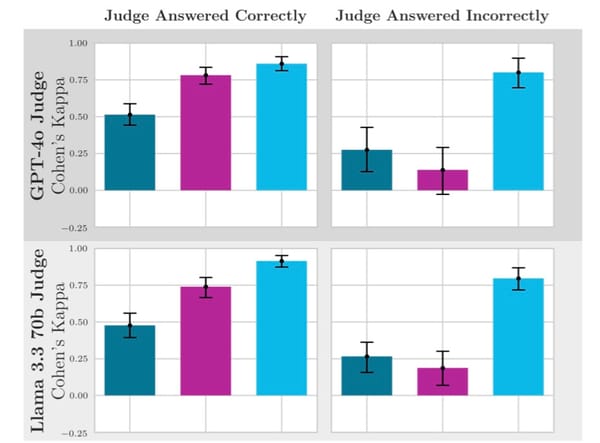
Dr. P: Looking at your error analysis in Figure 3, I'm struck by the comparison between Llama, ToolAce, and CoALM on API-Bank and BFCL V3 tasks. Could you elaborate on the specific types of errors that CoALM still makes versus those that it addresses compared to other models? And what does this tell us about the remaining challenges in unifying conversation and tool use?
Author: Figure 3 provides a revealing comparison of error patterns across the models. Let me break down what we found:
For API-Bank L1 (top row of Figure 3), the error analysis shows:
- Llama 3.1 8B fails by missing functions entirely. In the example, it only generates a ModifyReminder function call while completely omitting the required GetUserToken function.
- ToolACE shows a different error pattern – it attempts both function calls but uses incorrect values for critical parameters (wrong token value).
- CoALM 8B correctly generates both function calls with proper parameter values, demonstrating its ability to understand the sequential relationship between API calls [Section 5.3].
For BFCL V3 parallel function calls (bottom row):
- Llama 3.1 8B uses wrong syntax for function calls (improper formatting).
- ToolACE misses some functions (specifically the chai tea and coffee entries).
- CoALM 8B correctly identifies all food items and generates properly structured function calls for each [Section 5.3].
The remaining challenges for CoALM include:
- Multi-turn function calling accuracy, which remains relatively low (28.25% for CoALM 405B in Table 4). This suggests difficulty in maintaining context for function calls across multiple turns.
- Complex nested function calling scenarios where dependencies between functions need to be understood.
- Balancing performance across different capabilities – as we saw with the CoALM 405B performing slightly worse on JGA despite its larger size.
These challenges point to fundamental tensions in optimizing for both conversation and tool use simultaneously [Section 7].
HoL: I notice that in Table 5, when you removed the CRA dataset, JGA actually improved slightly (from 30.4% to 34.5%), even though Success Rate dropped. This seems counterintuitive. What's your interpretation of this result, and what does it tell us about the interaction between different training components?
Author: That's a very perceptive observation about the seemingly counterintuitive result in Table 5. When we removed the CRA dataset, JGA improved from 30.4% to 34.5%, while Success Rate dropped from 51.6% to 50.0%.
This result reveals an interesting tension between different skills. The JGA metric measures the model's ability to accurately track dialogue states (slot values) throughout a conversation, while Success Rate measures task completion – whether the system successfully provided all the information requested by the user.
My interpretation is that the CRA dataset, with its focus on ReAct reasoning and API calls, might actually be competing with pure dialogue state tracking for the model's capacity. When we remove CRA, the model can allocate more attention to precisely tracking dialogue states (improving JGA), but it loses some ability to reason about and complete multi-step tasks (reducing Success Rate).
This suggests that certain types of reasoning may be in tension within the model's parameter space. The ReAct-style reasoning introduced by CRA helps the model decide when to make API calls and how to interpret results, which benefits task completion. However, this reasoning pattern might be slightly different from the pattern needed for optimal state tracking.
It's worth noting that when removing TOD data, both Success Rate and JGA decrease significantly, confirming that the TOD component is essential for state tracking. This result highlights a fundamental challenge in building unified models: different capabilities may compete for model capacity, and optimization objectives don't always align perfectly [Section 5.4].
LaD: Let's talk more about the data balance in your training mix. Table 1 shows you have 13K SNIPS samples, 216K function calling samples, and 82K CRA samples. Did you experiment with different ratios? How did you determine this particular distribution was optimal, and how sensitive is model performance to changes in this balance?
Author: The data balance question is extremely relevant. The distribution shown in Table 1 represents our final configuration, but it wasn't determined arbitrarily.
We didn't systematically experiment with all possible ratios due to computational constraints, but our approach was informed by both practical considerations and preliminary experiments:
- For SNIPS, we used the complete available dataset after transformation. While this led to fewer samples compared to other components, the samples were high-quality and focused specifically on dialogue state tracking, which is a core TOD skill.
- For function calling, we initially included only Hammer (13.8K samples), but found that adding ToolACE's multi-turn examples (202.5K samples) significantly improved performance on function calling benchmarks. The larger proportion of function calling samples reflects the complexity and diversity of this task.
- For CRA, we generated 82K samples, which represents a middle ground. We found that fewer samples led to insufficient learning of the ReAct reasoning pattern, while generating significantly more would have been computationally expensive and potentially led to overfitting.
Our ablation studies in Table 5 indirectly address your question about sensitivity. When we removed individual components, we observed significant performance drops in related tasks:
- Removing LA datasets reduced API-Bank Rouge-L1 by 47.3% and BFCL success by 18.3%
- Removing TOD datasets decreased JGA by 11.0% relative to CoALM
- Removing CRA impacted both MultiWOZ Success and API-Bank metrics
This suggests that the model is indeed sensitive to the presence of each data type, and our mixture provides a reasonable balance [Section 5.4].
Indus: From an industry perspective, I'm interested in the practical applications and deployment considerations. Could you discuss the computational requirements for training and inference with your models, especially the 405B parameter version? Also, how do you envision CoALM being used in real-world applications?
Author: From a practical standpoint, the computational requirements are significant but manageable with current infrastructure. For training, we used 8 NVIDIA H100 GPUs for all our models. CoALM 8B required approximately 8 hours of training, while CoALM 70B took about 60 hours.
For the much larger CoALM 405B, we leveraged QLoRA with quantization to normalized float 4 (nf4) to improve efficiency. Still, inference with CoALM 405B requires 16 H100 GPUs, which is a considerable resource requirement. We acknowledge this as a limitation that may restrict accessibility for some researchers [Section 7].
For real-world applications, we envision CoALM being deployed in scenarios requiring both natural conversation and diverse tool usage, such as:
- Customer service platforms that can maintain context across multiple turns while accessing various backend systems (reservation systems, knowledge bases, etc.)
- Virtual assistants that can handle complex multi-step tasks requiring both dialogue (clarifying user needs) and API calls (executing actions)
- Enterprise systems where users need natural interactions with multiple business tools
The key advantage is adaptability to new services without expensive retraining. When introducing a new API, CoALM can incorporate it without the extensive prompt engineering or fine-tuning required by specialized systems.
Production challenges include latency (multi-turn reasoning increases response time), cost-effectiveness, safety (ensuring proper handling of sensitive operations), and integration with existing systems [Section 6].
A: We've had a great discussion covering many aspects of the CoALM paper. To summarize today's key insights:
- CoALM successfully unifies traditionally separate capabilities: multi-turn dialogue management from TOD systems and flexible tool use from Language Agents.
- The CoALM-IT dataset, especially the novel CRA component with explicit reasoning steps, proved crucial for integrating these capabilities.
- Results across MultiWOZ, API-Bank, and BFCL benchmarks demonstrate that a single model can excel in both conversational and function calling tasks.
- The ablation studies revealed interesting tensions between different optimization objectives, highlighting the challenges of multitask learning.
- Limitations include computational requirements for larger models, potential trade-offs between skills, and the need for more efficient architectures for practical deployment.
Future directions point toward reinforcement learning for continuous improvement, more efficient architectures, and enhanced multi-turn function calling capabilities.
Emre, could you share the five most important citations that readers should explore to understand the foundational work that your paper builds upon?
Author: Certainly! Here are the five most important citations for understanding the foundational work our paper builds upon:
- Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K., & Cao, Y. (2023). ReAct: Synergizing reasoning and acting in language models. This paper introduced the ReAct framework that combines reasoning and acting, which we extended for multi-turn conversational settings.
- Schick, T., Dwivedi-Yu, J., Dessì, R., Raileanu, R., Lomeli, M., Hambro, E., Zettlemoyer, L., Cancedda, N., & Scialom, T. (2024). Toolformer: Language models can teach themselves to use tools. This work pioneered how LLMs can autonomously learn to use external tools.
- Hudečk, V., & Dušek, O. (2023). Are large language models all you need for task-oriented dialogue? This paper examined the dialogue management abilities of instruction-tuned LLMs in handling goal-oriented multi-turn conversations.
- Lin, Q., Wen, M., Peng, Q., Nie, G., Liao, J., Wang, J., Zhou, J., Cheng, C., Zhao, Y., & Zhang, W. (2024). Hammer: Robust function-calling for on-device language models via function masking. This work developed approaches for effective function calling that informed our training methodology.
- Rastogi, A., Zang, X., Sunkara, S., Gupta, R., & Khaitan, P. (2020). Towards scalable multi-domain conversational agents: The schema-guided dialogue dataset. This paper introduced the Schema-Guided Dialogue dataset that we transformed to create our Conversational ReAct API dataset.
A: Thank you, Emre, and thanks to everyone for your insightful contributions to today's discussion. The paper presents a significant advancement in unifying conversational and tool-use capabilities in language models, with promising implications for both research and applications.